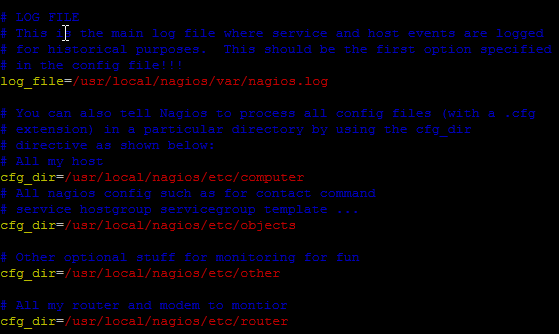
E’ sufficiente una configurazione minimale… Le possibilita’ sono molteplici, quella che
preferisco richiede due sole modifiche al file /etc/nagios/nagios.cfg:
A questo punto e’ sufficiente inserire i file di configurazione nella directory myConf
sperimentando un poco! Un esempio e’ riportato nel seguito. In ogni caso, ad ogni modifica
della configurazione, e’ opportuno lanciare Nagios in modalita’ di controllo:
nagios -v nagios.cfg
Abilitare gli utenti
Ora bisogna autorizzare gli utenti creati con Apache all’utilizzo del CGI agendo su
/etc/nagios/cgi.cfg. Nagios consente di definire in modo molto selettivo i permessi. Un
modo semplice e’ quello di autorizzare nagiosadmin a tutto o quasi scommentando i vari:
#authorized_*
Attivare Apache e Nagios.
Si tratta di servizi:
– service http start
– service nagios start
Ora funziona tutto.
Basta collegarsi su http://nomeserver/nagios e si entra nella Home Page!
Configurazione
Il file di configurazione di default di Nagios e’ /etc/nagios/nagios.cfg. Se si vuole impostare
una configurazione significativa e’ molto importante strutturare bene i file di configurazione.
La modalita’ piu’ semplice e’ quella di inserire le diverse clausole direttamente nel file
principale ma il mio consiglio e’ quello di creare una directory ed all’interno di quella piu’ file
organizzati per tipologia di direttiva.
Configurare Nagios non e’ difficile e l’approccio pragmatico e’ il migliore. Quindi conviene
provare immediatamente ed inserire nuovi oggetti a poco a poco. Vediamo quindi qualche
semplice configurazione.
I principali oggetti in Nagios sono gli host che ospitano service e che vengono controllati
con gli opportuni command. Nell’esempio sono configurati due host che vengono controllati
con un “ping”. E’ inoltre definito il controllo di un servizio web su cui viene verificato il
contenuto della pagina. La verifica segue eventuali redirect ed e’ indipendente dagli indirizzi
dei server (come deve essere per verificare le piu’ complesse configurazioni con proxy,
cluster, …). La definizione degli elementi di configurazione di Nagios utilizza una logica object oriented.
Quindi le opzioni vengono “ereditate” consentendo cosi’ una definizione piuttosto snella e
modulare di ambienti anche complessi.
E’ possibile definire anche altri aspetti quali raggruppamenti di host e servizi, gruppi di
operatori ed i loro diritti, orari di servizio, coordinate dei server per una visione in 3D, …
define hostgroup{
hostgroup_name production
alias Production Servers
members web1.acme.it,web2.acme.it,db1.acme.it
}
define hostextinfo{
host_name web1.acme.it
notes Application Server 1
icon_image linux.png
icon_image_alt Web Server1
statusmap_image linux.gd2
2d_coords 200,75
3d_coords 200.0,75.0,50.0
}
Le diverse definizioni possono essere poste su un unico file oppure, meglio, separate per
tipologia di oggetto e di servizio e raccolte nella directory indicata in nagios.cfg.
Plug-in
Il controllo dell’effettivo fuzionamento di un servizio avviene mediante un comando interno
di Nagios oppure mediante un Plug-in.
Il numero di Plug-in e’ molto elevato e ciascuno consente un controllo molto completo delle risorse per le quali e’ stato sviluppato.
Ad esempio e’ possibile controllare se un sito web e’ attivo, se ad una richiesta risponde
con una pagina che contiene uno specifico testo, se il certificato server utilizzato dal
protocollo HTTPS e’ in scadenza, se la pagina viene reindirizzata, …
Quanto riportato e’ relativo al solo Plug-in check_http che supporta una ventina di differenti
opzioni. I Plug-in ufficiali sono una cinquantina e si trovano in /usr/lib/nagios/plugins. I
controlli possibili sono i piu’ svariati: connettivita’ di rete, presenza di servizi, utilizzo del
sistema operativo, corretto funzionamento di database, …
I plug-in possono essere provati in modalita’ interattiva, quindi la configurazione di nuovi
controlli e test risulta semplice e veloce:
./check_oracle –help
Restituisce un help sulle diverse opzioni fornite dal plugin (e’ anche possibile utilizzare
l’opzione in formato short: -h).
E’ possibile sviluppare nuovi plug-in seguendo le semplici linee guida pubblicate. Tale
eventualita’ e’ diventata tuttavia piuttosto remota poiche’ i plug-in disponibili sono gia’ molto
completi e quindi tipicamente si utilizzano quelli presenti con eventuali piccole modifiche.
Le caratteristiche di base di un plug-in sono molto semplici. Deve essere un programma
eseguibile scritto in un qualsiasi linguaggio, che possa ricevere eventuali parametri, che
restituisca su stdout una stringa con il risultato del controllo ed un codice d’errore secondo
la seguente logica: 0=OK 1=WARNING 2=CRITICAL 3=UNKNOWN.
Oltre ai plug-in e’ possibile attivare controlli esterni. Nagios legge periodicamente da un file
le direttive di comandi esterni che possono contenere richieste di configurazione o i risultati
di un controllo (PROCESS_SERVICE_CHECK_RESULT).
In questo modo integrare Nagios con altri strumenti e programmi di monitoraggio risulta
molto semplice.
Utilizzo
L’utilizzo di Nagios e’ molto semplice. E’ lui a lavorare in modo continuo ed a controllare i
sistemi ed i servizi che sono stati configurati. Generalmente si utilizza la pagina di dettaglio dei servizi ordinata per stato (ma anche altre come la “Tactical Overview” o la “ServiceGroup Summary”) per avere su console lo stato complessivo di tutti gli ambienti evidenziando eventuali problemi.
Quando Nagios rileva un problema lo evidenzia sulla console e scatena tutte le azioni
configurate (eg. invio di email). Quando un operatore prende in carico il problema Nagios
interrompe le escalation e riporta sulla console l’indicazione di lavori in corso.
Nagios effettua i controlli in modo intelligente. Se un server risulta e’ in down ovviamente
non saranno utilizzabili tutti i servizi su esso definiti; Nagios non effettua controlli inutili ed
invia una sola notifica d’errore.
Se e’ stata configurata in modo corretto la topologia della rete (con l’opzione <parent>
dell’oggetto host), Nagios puo’ distinguere tra un sistema in down ed un sistema non
raggiungibile perche’ un componente intermedio della rete e’ in fault. Anche in questo caso
non vengono effettuati controlli inutili e vengono inviate solo le notifiche richieste.
E’ possibile effettuare da web diverse attivita’ di controllo e gestione (eg. controlli a
richiesta, interruzioni di servizio programmate, …). Dal punto di vista funzionale sono
coperte tutte le esigenze di una linea di servizio operativa sulle rete e sui sistemi.
Come si conviene ai piu’ completi strumenti di monitoraggio, sono disponibili sofisticate
funzioni di statistica e reportistica.
– / 5
Grazie per aver votato!
Vuoi abilitare le notifiche?
Desiderate avere la possibilita’ di ricevere delle notifiche? Se si avrete la possibilita’ di essere sempre aggiornati con le nostre ultime proposte o notizie . Consigliamo l’adesione Grazie !
Attiva
How useful was this post?
Click on a star to rate it!
Average rating / 5. Vote count:
No votes so far! Be the first to rate this post.
As you found this post useful...
Follow us on social media!
We are sorry that this post was not useful for you!