I file di testo contengono un flusso continuo di caratteri in nessun formato predefinito. Sebbene alcuni formati di file si siano sviluppati su file di testo (ad es. JSON , YAML ), che si aspettano che i dati di testo siano presenti in un formato particolare, i '.txt'file normali non hanno tali convenzioni. Quindi, il recupero di una specifica riga, frase o stringa da un file di testo deve essere eseguito utilizzando strumenti Linux generici.
Il comando grep in Linux viene utilizzato per trovare una sottostringa o un modello di testo, in una stringa o in un file. Stampa la riga in cui si trova la sottostringa.
La sintassi per l’utilizzo del comando grep è la seguente:
$ grep <sottostringa> <nome file/input standard>
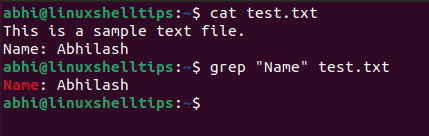
Ad esempio, per cercare la sottostringa ” Nome ” nel file ” test.txt ” (il cui contenuto è mostrato nello screenshot), eseguire quanto segue.
$ grep "Nome" test.txt
Oggi vedremo come estrarre gli indirizzi email dai file di testo utilizzando il comando grep .
Come sappiamo, un indirizzo Email è presente nel formato:
<user_id>@<dominio>.<sottodominio>
Qui, user_id è una stringa identificativa univoca scelta dall’utente e dominio e sottodominio rappresentano il provider di servizi di posta elettronica (ad es. gmail.com ).
I nomi di dominio e sottodominio possono contenere solo alfabeti, mentre user_id può contenere alfabeti, caratteri numerici e altri caratteri comuni come punto (.)e trattino basso (_).
Poiché questo è un modello definito che deve essere cercato, possiamo usare il '-e'flag di grep, che ci consente di specificare modelli di espressioni regolari invece di sottostringhe, per l’estrazione da un file.
Pertanto, la sintassi di grep con '-e'è:
$ grep -e <espressione_regolare> <nome file/input standard>
Sulla base del modello di un indirizzo e-mail discusso in precedenza, possiamo formare la seguente espressione regolare:
[a-zA-Z0-9._]\+@[a-zA-Z]\+.[a-zA-Z]\+
Qui, 'a-zA-Z'rappresenta qualsiasi alfabeto, '0-9'rappresenta numeri, '._'rappresenta un punto o un carattere di sottolineatura. Nota che i caratteri '\+'rappresentano che il set di caratteri tra parentesi dovrebbe apparire una o più volte.
Eseguiremo questa espressione regolare per estrarre gli indirizzi e-mail dal file ‘ test2.txt ‘.
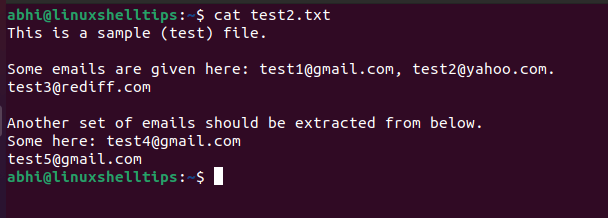
Innanzitutto, visualizza i contenuti del file test2.txt :
$ cat test2.txt
Quindi, esegui il seguente comando per estrarre gli indirizzi e-mail dal file.
$ grep -e "[a-zA-Z0-9._]\+@[a-zA-Z]\+.[a-zA-Z]\+" test2.txt

Come possiamo vedere, gli indirizzi Email sono stati identificati con successo da Grep. Tuttavia, vengono visualizzati insieme alla riga completa nel file.
Per visualizzare solo gli ID e-mail trovati, utilizzare il '-o'flag insieme a '-e'come mostrato.
$ grep -oe "[a-zA-Z0-9._]\+@[a-zA-Z]\+.[a-zA-Z]\+" test2.txt

Conclusione
In questo articolo abbiamo visto come estrarre indirizzi email da un file di testo in Linux, utilizzando il comodo strumento da riga di comando Grep .
